
One reader with the pleasant name of Marlon wrote in one comment recently the following great question, and thus coaxed me to impart some advanced goldlisting knowledge which I was keeping back for the book:
Hello,
I am eager to start the Goldlist method. However, I need further clarification about scheduling. I read your post responding to Abdul some years back but I am still not sure how I can avoid distillations and new headlist overlapping. I do understand I could simply insert a batch of words and not use the step system, but it is not my desire to take that route.
I would prefer to use the step Goldlist method. I think I am most confused by time allotment. I decided to use the 20mins/25words/10min break format. When distilling to the first set (from 25 to 17), I believe you suggest use the same format, that is to use 20mins/25words/10mins. What about D2? Do I still need to use 20 mins to go from D1–>D2 (and D2—>D3)? In other words, do I perform as many distillations as possible after D1 is completed in the 20 min allotment? For example, Would it be prudent to distill maybe 2 sets from 17–>12 in one 20 min block?
I am looking forward to your response.
I will write the answer to this as a main article, partly because it’s a better way to get more readers to read it, and it is a good and useful topic for those who are using the Goldlist, and partly because I can use tables better in a new article than in a response.
I think it’s an excellent question, which shows that you’ve understood most of what I need you to understand in order to work successfully with the method.
I have in the past left people to fill in the blanks for this one themselves, as there are a number of ways in which you could fill in the blanks and they would all be good as long as the basic tenets are agreed to, and also I was leaving something back for the book, but just to give you an example of what works for me, imagine that you decide to do a project in which you have a good idea how many lines will be in the headlist in total, and lets say it’s going to be 3000 lines of headlist.
I would split that task into Batches, and each batch I give letters of the Alphabet, so Batch A, Batch B, etc.
Now because we want to avoid running into within two weeks of ourselves, as well as not have too long periods of not getting to review the same material (more than a quarter of a year is not necessarily harmful, but means you have little momentum, in practice, which can be demotivating) we need to plan it so that the first batch is the biggest batch, and then they get gradually smaller.
So the last batch will be 100 words, the second from last will be 200 words, etc.
Now follow me through this logic:
Batch Cumulative Number (backwards)
100 – 100
200 – 300
300 – 600
400 – 1,000
500 – 1,500
600 – 2,100
700 – 2,800
800 – 3,600
(BTW – You can do the above triangular number calculations with a short cut, (n*n+1)/2 where n is the number of batches. If you want 8 batches, then 8*9 is 72 and half of that is 36. 36 hundreds is 3,600.)
We see from this that to do 3,000 words it’s good to start with 700 plus the difference between 2,800 and 3,000, ie 900, then 600, 500, etc. You can do the same with other project targets and come up with other similar batch plans, but here for 3,000 lines in the headlist, I’d say the batch plan would look like this:
Batch A: 1-900
Batch B: 901 – 1,500
Batch C: 1,501 – 2,000
Batch D: 2,001 – 2,400
Batch E: 2,401 – 2,701
Batch F: 2,702 – 2,900
Batch G: 2,900 – 3,000.
You then approach the project by doing things in this order…
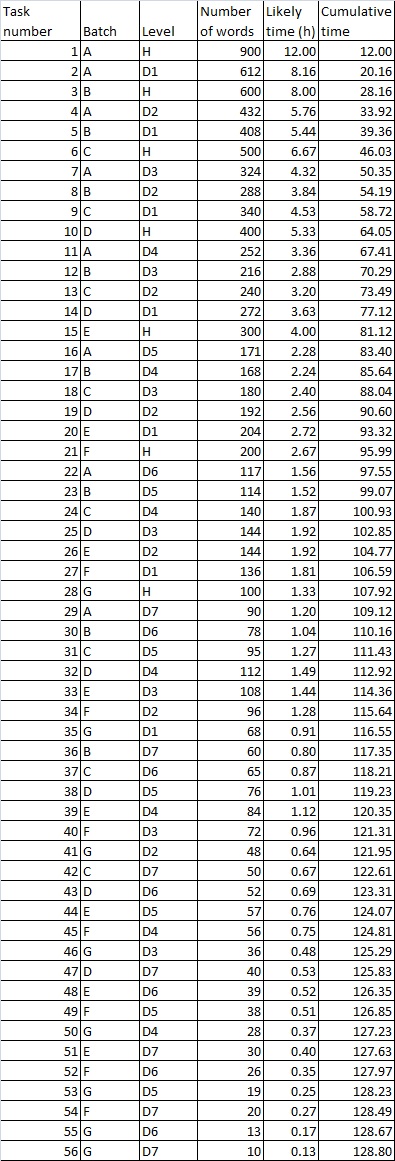
Let’s say that you are spending 3 hours per week on this linguistic project, which means you have the intention of doing it over a ten-month period, which with slippage might be an annual period. The above table also assumes you are taking it to the end of the silver book. You might take it to gold book distillations namely D8 through to D11 after finishing the whole project to silver, which is the way I do it, or do the gold the same way in which case you will adapt the above programme accordingly. D12 is something that also exists – but not in the goldlist books. In D12 you take your final list of hardest words, distilled one final time for good measure and where you put them is on an order form for merchandise at something like Cafepress and then you have these few words on T-shirts, mugs and things. That is how you honour the words and phrases that eluded your memory in the Goldlist system. They are, after all, your personal gold and they have an interesting relationship already with your unconscious mind. If you are giving this 3 hours a week, then you are able to fit well within the 3 weeks at the critical initial stage.
The hardest “run” (which is what I call working through all the existant and open batches in order) is quite early on. When doing task 11 you would be looking at words you saw 7 weeks ago if working at 3 hours a week. To keep momentum at this part of the project a person might want to put in additional hours.
The total number of runs in the whole project is 14 runs including the two runs at the start and the finish which have only one task, the two middle ones which have twelve tasks each (although they aren’t the runs with the greatest amount of work, which come earlier because we are using declining batch numbers – the exact way this pans out depends on how you plan your batches).
The problem of course comes when you get to the later tasks – in fact even from task 39 you can’t keep spending 3 hours a week on this project without catching up with yourself. This is where slippage will start to come in. The final run only wants ten minutes of work to be done in the course of two weeks. But we are talking about only the last 10% of the work. The last 10% of the work is in 6 of the 14 runs. There are two ways around this, one is to increase the size of the final runs so that instead of going 300, 200, 100 for runs E, F and G we have 300, 200 and 300 respectively. Or make 300 the lowest run you do when you do the triangulation plan. You get the general idea and you can play with it. It is not an exact science – in any event there could be weeks when you need to be on holiday, or don’t feel well, or weeks when you can’t resist working more than the plan and unexpectedly come up to the two week barrier even though you weren’t expecting to.
Another way of dealing with the lag at the end for the last 10% of the project is to simply start your next project. Having a few languages on the go in Goldlist at once, all at different levels means that you always have something you could be doing to keep working and yet forestall breaking that fortnight memorial curfew.
It goes to show that a linguistic project of 3000 words and batched out like that is good for someone who has 3 hours a week to spend on this. If someone is planning to spend 6 hours a week, then the thing to do is to plan a 6000 line project and go through all the above steps, from the triangular number calculation forward. Again this gives a very manageable batching plan for that time budget.
Please note as an aside that runs can also be given a name or a number. A run starts with the oldest batch which you are still distilling and ends with the last thing being added to the headlist or the last things which had been added to the headlist if there is no fresh headlisting at the end of the given run. The function of number of runs to number of batches will be R=B+L-1, where R is the number of runs, B is the number of batches and L is the number of levels you are using, including the headlist. With writing-book based Goldlisting, the value for L will usually be 8, 12 or 4 if you only want to take a certain list to bronze level. Runs are an important concept to have in mind when working with batches as the two really go hand in hand, and the run length is what you have to manage so that it doesn’t go under 2 weeks or over something like three months which really tends to give a sense of drag. It is useful to have three months that as an outside goal post – or you can make it two months but three gives a bit more flexibility – but it’s not critical to the process as the minimum two-week one is.
Answering your other question, namely how to do 20 minutes in non Headlist scenarios, what you would do is pro-rate the time, so that you are still working to 20 minute blocks. Often you will find that you can do two pages of D1, 3 pages of D3, 4 pages of D4 in one sitting. If it is not feeling comfortable and interesting, or takes you much over 20 minutes without a break, then stop for a break and continue later. There is nothing the matter with stopping the day’s work half-way down a page of distillation as long as you have left a mark to point out where you are the next time. Otherwise you might just start the next page and forget to distil half of the last page you were looking at.
I hope that has answered your doubts and made the system more useable and pleasurable for you, as well as been useful for other users who will no doubt be as grateful as I am for a good question.
Dear Viktor,
I have been using the method for a few weeks now and I have some (pleased) reflections, questions, and anecdotes to share when I have a chance to write them up. For now, I’ve got one question: it seems that I haven’t yet seen a name for one segment of any given list or distillation (in the headlist, this would be any one of the 25-word groups that appears on one pair of facing pages). Have I overlooked it?
In a headlist, this could be a group of words numbered 126-150. In the first distillation, a group of words numbered 18-34, for example. I would find it helpful to have a name for this grouping. Segment? List segment? Sublist? Partial list? Word group(ing)? Element group(ing)? Lexeme group(ing)?
If a term has been put into use, pardon my oversight. I will happily adopt it. If not, any handy term agreeable to you and to the community is fine with me.
I look forward to further conversation regarding the Method!
David
That’s a good point, I didn’t “publish”, as it were, a word for that, but I think that the term “page” or “page worth of” is what I’ve used in my own mind for this concept. Thanks for the excellent question, David, and I look forward to your forthcoming inputs.
Aha! The first comment was simply awaiting moderation but wasn’t show up in my account for some reason. Thanks for the reply. Yes, now that you say it, simply using ‘page # of headlist/distillation x’ makes perfect sense. Until later!
Hasta luego, Che.
Dear Viktor and community,
I prepared a briefer version of this comment a week or so ago after signing into WordPress. Upon clicking ‘Post Comment’, however, and being asked to log in again, my post seems to have vanished into the ethers (a problem not encountered with paper and pencil). I thought I had learned to make at least copy and paste backups. Oh, well, this comment benefits from further time for reflection.
Anyhow, I’ve been interested in the Goldlist since I discovered it in February of this year (2014). I began actually using it a month ago. Everything is well-explained, -supported, and -defended on the site. Thanks for sharing it with all of us.
There are several (pleasant) reflections, anecdotes, observations, and questions that I’d like to share as I find the time to write them up. For now, I’ve got a couple nomenclature questions. Is there a term in use for any given group of 25, 17, 11, or 8 words (to cite the ratios I’m using)? These could be numbered 151-175 on the headlist, for example, or from 35-51 in D1. Namely, this would be any one block of words that appears in one of the four identified regions of one facing-page pair. If a term has been convened upon, I’ll happily adopt it. If not, may I nominate some possibilities?
– Sublist
– Headlist/nth distillation segment/section?
– Lexeme/word/item group(ing)?
– Vintage (with analogy to wine aging)
– Corner?
– Installment (perhaps my personal favorite—it’s a word
my mother and grandmother would use)
And how about any given completed facing-page spread taken as a whole? With inspiration from the image used in , could we call the joint aggregation of one headlist sublist plus its first three distillation sublists a shell or spiral, as it is here on the facing-page spread that the geometry and elegace of the Goldlist are most transparently visible? Perhaps a cluster or coil or course? I think _shell_ or _spiral_ would be my personal favorite for this one.
It seems useful to have such terms when tracking the location of a word in, say, a Silver book back to it’s first appearance in the applicable Bronze book. Or is all this nomenclaturizing just gratuitous? Then again, Strong’s Concordance and Morohashi’s dictionary (yes, I’d put the Goldlist alongside these figures in utility and importance) have multi-layered intra- and interreference number systems for a reason.
That’s all for now! As I say, I look forward to sharing more as I find the time. Until then,
David
P.S. That fourth paragraph was supposed to include a link to another posts of yours. Let’s see if I can insert it this way: http://huliganov.tv/2011/03/03/1834/
I thought you were referring to that image, which isn’t my authorship by the way, it was offered by the system that used to exist to find images for posts, but I liked it, because in fact it shows two spirals – the one in the snail’s shell and the other is the CD’s laser track on which the shell is resting.
To an extent this post covers what you wrote and I just answered, but there is a bit more here, so I will add to what I wrote on the last one: I like the idea of the use of the term “spiral” – it is quite “inspired” if you’ll pardon the pun, and I thing that having well-defined nomenclature is very useful. This enables users to be able to discuss, seek help or give it with others using a common language.
All right! I’ve finally sat myself down to type out my experiences and reflections on using the Goldlist system for my own language projects. I’ll chunk them into individual comments for manageability.
Discovery
I discovered your (David James’s) autobiographical account beginning on page 418 of _The Polyglot Project_ (2010, ed. Claude Cartaginese), in early 2014. I believe it had been a _Fluent in Three Months_ reader who forwarded the post to me. Your story led me to your YouTube channel, which I then followed through to Huliganov.tv with its description of the Goldlist.
Many thanks for all your comments today, David. I am glad to hear these reflections after the first year of your use of the Method and I see that you are now really comfortable with it and get what it is about. I imagine that like me and many others you will carry this technique through life and use it in many learning projects, maybe some even outside of language learning too. I hope that you will check back in from time to time with your progress reports, and also that you’ll share the Method with your friends.
Indeed, it has become a part of my life. I now evaluate all notebook purchases for their Goldlist suitability and have even been known to look gift horses in the mouth (but only after the horse-gifter has retired) under the influence of the Goldlist.
The Goldlist is an example of what I think _innovation_ is really about: taking the discoveries of research, applying scientific principles, and using it all to recombine the known and familiar in order to solve concrete problems in demostrably superior ways. Not throwing a bunch of molded plastic gimmickry at the wall to see what sticks and trying to get rich by psychologically manipulating everyone in thinking it must be bought.
Your decision to have gifted us the method is admirable and appreciated. I hope your future books add financial returns to the pleasure you must experience at seeing your method adopted and appreciated by so many. Thank you again for this tool. It is indeed a lifer.
Many thanks for these warm words. Don’t miss the GoldList Method User Group on Facebook which is where we do the 70 day challenges.
Initial Attraction and First Uses
Before encountering the Goldlist, I had repeatedly noticed that When I learn items or sequences to memory, be they literary, scientific, or historical, one of the most invaluable pointers that takes me directly to where I most need to focus my attention is when I catch myself forgetting or misremembering something. If I forget a specific line or lyric to a song I am learning, for instance, or get multiple lines out of sequence, I no long feel frustrated by the experience but take the opportunity to reexamine the cohesion in the transitions immediately surrounding the mistaken portion and the relationships that portion has to adjacent lyrics and to the larger overall song structure, thus thickening the neural network around that mistaken portion. Having noticed this about myself, my interest was piqued by a system whose central architecture is precisely a _systemization_ of this forgetting. In such a system the forgetting is more intentionally and proactively harnessed in an organized way so as to automatically direct the learner’s efforts to precisely those spots where they are most needed without wasting time on areas where they aren’t needed. (It’s worth noting here that the word _effort_ in this paragraph doesn’t necessarily mean, for my purposes, undesirable overexertions associated with the short-term memory; I use _effort_ here simply to mean the actions carried out, whatever they might be, in order to learn the data to memory.)
I had already studied Spanish as a second language for two years (some conversational night classes where I mastered my pronunciation but largely self-directed studies) and spoken it in legal, social, work, and home environments on a daily basis for some months when I encountered the Goldlist, but in the back of my bilingual dictionary I had been noting down fascinating new words from wherever I came across them. The list grew to cover several blank pages at both ends of my cheap dictionary with small handwriting, but with working full time (yea, often double time) and the all-important routines of home life, I had not yet organized any way of learning that vocabulary systematically.
Furthermore, I knew that the techniques I’d used to study languages as a full-time linguistics student with little to no social or family life (however voluntary my studently isolation) were dependent on the luxury of large quantities of uninterrupted time, and I feared what would happen to my linguistic aspirations outside of such a time-rich context.
The Goldlist presented itself as a potential way to begin processing these Spanish vocabulary items effectively and efficiently and to take me through other long-range projects that had been either sidelined or outright delayed for lack of free time. I have now used it for a year and taken my first Goldlist at a very relaxed (and oft-interrupted) pace to a Headlist of 600 literary, regional, colloquial, or otherwise uncommon words in Spanish. About two thirds of that headlist have been distilled down to D3, as I was eager to confirm the efficacy of the enforced forgetting period for myself. I don’t have a specific numeric goal for the project, but my list of found vocabulary only keeps growing the more I read and listen. I could easily see this project reaching a headlist length of five thousand words over time.
. . . I no _longer_ feel frustrated . . .
Reflections and Tweaks – Personalized
In this initial tryout of the system, I got a feel for the system and how my habits could best adapt to it. I found that I, as some of the other users referenced in places on the blog, was being a bit too “perfectionistic” and making it
too difficult for myself. For instance, I was attempting to include all possible meanings for a given homophonic unit of spelling (_cleave_ and _cleave_, to cite an English analogy) as well as common phrases or expressions with these words _all on the same line_. This made it difficult to remember enough information to distil sufficient tokens from some distillations. As my combined lines piled up on me much more rapidly than I’d have prefered, the conversation here (and on interlinked sites) helped me realize that I needed to include just one “unit” of information per line. I suspect that what comprises a “unit” for an individual is interrelated to N+1 and the zone of proximal development because a quantity of information that lands in an area of the brain with already dense neural networks would be more easily remembered than an equal quantity that lands in a sector with relatively sparse neural networks. But allowing for that sometimes overload, I did find (slightly to my surprise, I must admit) that absences of even three and four months in length did not erase vocabulary from my mind once it had been distilled out and (here I was even more surprised) that I was still able to distill off around thirty percent at whatever point I had left off a list.
Also, I had begun using H-D1-D2-D3 ratios of 25-17-11-8 that I assumed I’d carry throughout the Bronze book to the eventual Silver book. The distillation percentages for these ratios through to D7 are as follows:
25 > 17, -32.0 % D1
17 > 11, -35.3 % D2
11 > 8, -27.3 % D3 mean distillation percentage: 30.2
32 > 25, -21.9 % D4 range: 13.4 percentage points
25 > 17, -32.0 % D5
17 > 11, -35.3 % D6
11 > 8, -27.3 % D7
I’ve done the actual distillations in my list to only the D3 level, so far, but I did find that the volume of material moving through the distillations bunched up from time to time in some places (even when correcting for my overload) and thinned out to the point of sparseness in others. I don’t recall where I got the 25-17-11-8 scale, as the posts I’ve been seeing lately suggest a 25-17-12-8 ratio, but I do suspect that it will run more smoothly for me on average with 17 > 12 as my D2. I’ve also decided to use 32 > 24 for my future D4 and D8.
25 > 17, -32.0%, D1
17 > 12, -29.4%, D2
12 > 8, -33.3%, D3 mean distillation percentage: 30.2
32 > 24, -25.0%, D4 range: 8.3 percentage points
24 > 17, -29.2%, D5
17 > 12, -29.4%, D6
12 > 8, -33.3%, D7
If the calculation for these latter ratios is extended through to D11 at the end of the Gold book, the mean distillation percentage does creep down to 29.9 for the whole sequence, but I can live with one tenth of a percent below the target 30%, especially at the very closing stages of a project. (Did you notice that with 600 headlist items in a year, I’m not in a hurry? Just the same, I appreciate knowing that the time I have found for my vocabulary building has been used as efficiently as possible.) I do think that the quantities of material will move, on average, more evenly through the distillations, at least for me with my persnicketiness as to how well I’ve remembered an item (sometimes I’ll have a more or less vivid sensation or image or motion associated with the item, but I prefer to be able to recall a verbal equivalent, or at least a definition, before ejecting it!)
Future Plans
I am now confident that the Goldlist and I have adapted ourselves to each other and I’m very happy to be using it! I look forward to continuing it in Spanish and also applying it to Irish (now at 75 words on the headlist) and Russian and Finnish, although I’m not yet sure of my timelines.
It’s fantastic to have a system that is resilient in the face of interruptions, slowdowns, and competing priorities. The tangible physical accumulation of the filled pages, however slow, is most gratifying. And it is reassuring to have a “personal glossary” of, in my case, Spanish, because I often wish to actively produce a word I’ve learned but can’t remember it. While I don’t currently seek it out in my Goldlist book because I don’t want to violate the forgetting period (however unlikely that may be at my pace), at a later stage in the project I would feel perfectly comfortable perusing my completed Bronze books for a word that had been on the tip of my tongue at some point throughout the day.